Outils du Forum
Vous n'êtes pas identifié.
Publicité
[VGA] Architecture des GPU
Forum OvercleX
#1 2013-12-18 15:42:32
- Gael91
- New member

- Date d'inscription: 2013-11-15
- Messages: 20
[VGA] Architecture des GPU
Salut à tous, ce topic vous présentera les différentes architectures GPU AMD et Nvidia. Bien sur, il faut commencer par le début pour bien suivre l'évolution qu'il y pour atteindre les puces ultimes actuelles: GK110 et Hawai.
GeForce 8800 "G80":
En Novembre 2006, Nvidia sort la GeForce 8800 GTX. Basée sur la puce G80 de l'architecture TESLA, elle se compose de 681 millions de transistors gravés en 90 nm. La puce atteint une taille de 484 mm², énorme à l'époque.
L'architecture est de type unifiée. Au total, la puce contient 128 processeurs de flux répartis en en 16 blocs SM contenant chacun 8 processeurs de flux. En plus précis, la G80 dispose de 96 unités FMA32/INT et 16 SFU (Unités Spéciales). Le tout cadencé à 1350 Mhz. Sa puissance de calcul atteint les 346 GFLOP en virgule flottante 32 bits, 370 GIOP en INT24, 73 GIOP en INT32 et 17 GIOP en INT64. Notons que la G80 ne dispose pas de la virgule flottante double précision 64 bits.
Chaque bloc est relié à un groupe d'unités TMU (Utilisées pour les calculs textures 3D). Chaque groupe contient 2 TMU pour un total de 32 unités. Cadencées à 576 Mhz, la puissance théorique est de 18430 méga-texels/s.
La puce totalise aussi 6 contrôleurs mémoires 64 bits pour un bus de 384 bits G-DDR3 à 900 Mhz pour un débit atteignant 86.4 GB/s.
Chaque contrôleur G-DDR3 est relié à un groupe d'unités ROP (Calcul des pixels). Chaque groupe contient 4 ROP pour un total de 24 unités. Aussi cadencés à 576 Mhz, la performance théorique est de 13820 méga-pixels/s.
Notons également la présence d'un Raster Engine (Calcul des triangles) atteignant 576 méga-triangles/s.
Les dérivés sont la GeForce 8800 GTS 640 Mo avec 112 processeurs de flux (14 blocs SM), la GeForce 8800 GTS 320 Mo avec 96 processeurs de flux (12 blocs SM), et la GeForce 8800 Ultra qui est pareil que la GTX, mais surcadencée.
Radeon HD2900:
Basée sur l'architecture R600 PELE VLIW5, la Radeon HD2900 XT totalise 720 millions de transistors gravés en 80 nm. La taille de la puce atteint les 420 mm².
Au total, on compte 320 processeurs de flux. Mais étant vectoriels, on devrai plutôt dire 80 processeurs de flux x5. En effet, la puce possède 4 blocs contenant chacun 80 unités shaders ayant chacun une activité (ou un calcul). En précis, il y a 256 unités FMA32/INT et 64 SFU. Cadencés à 743 Mhz, la puissance théorique est de 475 GFLOP 32 bits. (Pas d'information concernant les calculs INT).
Chaque bloc est relié à un groupe de 4 TMU pour un total de 16 unités.A 743 Mhz, la performance atteint 11900 méga-texels/s.
Particularité de la R600: c'est le contrôleur mémoire. Non divisé par des contrôleurs 64 ou 32 bits, la R600 est régie par un "ring-bus", un contrôleur unique d'une largeur de 512 bits. A 828 Mhz G-DDR3, le débit atteint les 110 GB/s.
Ce ring-bus est relié à un 4 groupes de 4 ROP pour un total de 16 unités atteignant 11900 méga-pixels/s.
Tout comme la G80, il y a un raster Engine pouvant atteindre les 750 méga-triangles/s.
Les dérivés sont les HD2900 Pro qui est pareil que la XT , mais moins cadencée, et la HD2900 GT qui a un bloc de moins pour un total de 240 processeurs de flux.
La suite prochainement avec les GeForce 9800 G92 et les Radeon HD3800 RV670.
Vos question, et vos avis?^^
AMD RyZen 7 2700X, ASRock X470 Taichi, 16 Go DDR4-3200 G-Skill (2x8 Go), Radeon RX Vega 64, Samsung 970 EVO 256 Go+500 Go, 850 EVO 250GB
Hors ligne
#2 2013-12-18 17:26:05
- CornerJack
- Administrator

- Lieu: Belgique
- Date d'inscription: 2007-05-08
- Messages: 8812
- Site web
Re: [VGA] Architecture des GPU
Très sympa, je déplace dans la section Hardware ![]()
C'est de toi où tu as récupéré cela quelques part ?
Devenez un Lover'clex : http://www.facebook.com/overclex
Hors ligne
#3 2013-12-18 20:14:34
- Gael91
- New member
- Date d'inscription: 2013-11-15
- Messages: 20
Re: [VGA] Architecture des GPU
Cela vient de plusieurs sources, mais il a fallut fouillé des sites asiatiques pour que je puisse avoir la composition la plus détaillée possible d'une architecture GPU, comme les SFU, choses qu'on précise pas dans les sites chez nous...Mais ce que j'ai écrit est de moi...
AMD RyZen 7 2700X, ASRock X470 Taichi, 16 Go DDR4-3200 G-Skill (2x8 Go), Radeon RX Vega 64, Samsung 970 EVO 256 Go+500 Go, 850 EVO 250GB
Hors ligne
#4 2013-12-18 20:57:32
- Gael91
- New member
- Date d'inscription: 2013-11-15
- Messages: 20
Re: [VGA] Architecture des GPU
GeForce 9800 "G92":
La G92 fut sujet à des critiques et des avis divers. Certains parlent d'une plaisanterie, en vue des performances quasi identiques, d'autres d'améliorations, mais mineurs.
C'est un peu des deux personnellement, son architecture est certe en tout point identique à celle qui anime la G80, mais des modifications ont été apporté si on observe bien en profondeur, des modifs bien présentes, même si il faut admettre, elles n'apportent presque aucun gains de performance.
Le principal changement est la gravure qui passe en 65 nm (bien que AMD soit déjà au 55 nm avec les HD3800 que nous verrons après), ce qui diminue la surface de la puce qui tombe à 324 mm² avec 754 millions de transistors. Les autres changements sont assez illogiques en somme.
Les processeurs de flux ne changent pas: toujours 128 unités réparties en 16 blocs de 8 unités. A une vitesse de 1688 Mhz pour la GeForce 9800 GTX, elle atteint 432 GFLOP en 32 bits, 430 GIOP en INT24, 77 GIOP en INT32 et 17 GIOP en INT64
Mais ce qui change, ce sont les unités TMU qui passent de 32 à 64 unités, le double carrément. Les blocs SM se retrouvent donc avec des groupes de 4 TMU (2 avec la G80). Sous une fréquence de 675 Mhz, la performance théorique atteint 43200 méga-texels/s.
Autre changement important: les unités ROP, et la c'est un peu illogique. Alors que les TMU ont bénéficié d'une augmentation conséquente en nombre d'unité, les ROP ont le contraire: une diminution pour passé de 24 à 16 unités (Équivalant donc aux Radeon R600). Sous une fréquence de 675 Mhz comme les TMU, la performance atteint les 10800 méga-pixels/s, plus bas que la GeForce 8800 GTX.
Cette baisse du nombre de ROP entraine également la baisse de la largeur de bus mémoire. Elle passe en effet de 384 à 256 bits (Je vous laisse le soin des calculs si vous avez bien compris^^). Bien que la mémoire soit plus rapide en fréquence: 1100 Mhz, le débit a fortement diminué: 70.4 GB/s (Alors que la 8800 Ultra dépasse les 100 GB/s).
Les modèles G92 sont: GeForce 9800 GTX, GeForce 9800 GTX+ (surcadencée et bénéficiant de la gravure en 55 nm), la GeForce 9800 GT (avec 112 processeurs de flux) et la GeForce 9800 GX2, une double-puce. Notons aussi une GeForce 9600 GTX avec 96 unités shaders, mais réservée aux OEM.
Radeon HD3800:
Avec la déception des HD2900, AMD tente de résoudre les bugs et défauts en sortant la HD3870 alias "BOOM" RV670 (drôle de nom XD).
Gravée en 55 nm, elle possède 666 millions de transistors (diminution donc par rapport à la HD2900), sous une surface de 192 mm² (très petite donc).
Toujours avec ses 320 processeurs de flux répartis en 4 groupes vectoriels de 80 unités. Mais des modifications ont été faites de ce coté. L'ajout de la double précision, c'est ce qui la distingue de la concurrence. En précis, la puce contient 192 unités FMA32/INT, 64 unités FMA64/INT, et 64 SFU. En performance, la HD3870 avec sa fréquence de 777 Mhz atteint les 500 GFLOP en 32 bits et 100 GFLOP en 64 bits.
Le nombre d'unités TMU ne change pas: 16 unités réparties en 4 groupes de 4 unités. Par contre, des améliorations ont été effectué (Mais ce sera compliqué x![]() . A 777 Mhz, elles atteignent 12430 méga-texels/s.
. A 777 Mhz, elles atteignent 12430 méga-texels/s.
Le nombre de ROP ne change pas également: 16 unités en tout avec le même nombre de groupe. Pas mal de corrections ont été apporté aussi sur les ROP (une des origines des baisses de performances sur les HD2900). Les performances atteignent 12430 méga-pixels/s.
Autre changement important: le bus mémoire. Non seulement elle diminue drastiquement à 256 bits, mais aussi plus de ring-bus, mais des contrôleur mémoires 64 bits classique compatibles G-DDR4. En tout, 4 contrôleurs G-DDR4 64 bits. Sous une fréquence de 1126 Mhz, le débit est de 72.1 GB/s.
Toujours également un raster engine allant à 777 méga-triangles/s, et une unité de tesselation (Également présente aux HD2900).
Les modèles exploitant la RV670 sont: Radeon HD3870 et HD3850 (Également une HD3690 vendu qu'en Asie). Grâce à la consommation très faible des RV670 (une des plus grandes améliorations), deux modèles bi-gpu sont sorties: la HD3870 X2, et la HD3850 X2 (qui bénéficiera d'un modèle ASUS ROG).
La suite avec la GeForce GT200 et la Radeon HD4800^^
AMD RyZen 7 2700X, ASRock X470 Taichi, 16 Go DDR4-3200 G-Skill (2x8 Go), Radeon RX Vega 64, Samsung 970 EVO 256 Go+500 Go, 850 EVO 250GB
Hors ligne
#5 2013-12-19 07:48:40
- CornerJack
- Administrator
- Lieu: Belgique
- Date d'inscription: 2007-05-08
- Messages: 8812
- Site web
Re: [VGA] Architecture des GPU
Ok, attentions si tu repiques des phrases types de spécifier les sources, c'est toujours mieux ![]()
Bon boulot !
Devenez un Lover'clex : http://www.facebook.com/overclex
Hors ligne
#6 2013-12-22 00:18:06
- Gael91
- New member
- Date d'inscription: 2013-11-15
- Messages: 20
Re: [VGA] Architecture des GPU
GeForce GT200:
Après le succès des GeForce 8800, et l'amélioration des procédés des gravure, Nvidia sort l'architecture GT200.
Qu'y a t'il de nouveaux? Pas mal de choses on va dire. A l'inverse des GeForce 9800 qui n'ont rien apporté de plus concrètement, les GeForce GTX 200 sont issues des G80/G92, mais boostées. Les GT200 sont à l'image des Kepler qu'on a actuellement sur le marché.
On a en effet une puce ayant 1.4 milliards de transistors, un chiffre gigantesque pour l'époque. Mais Nvidia ayant opté au 65 nm pour la gravure pour économiser les couts, la puce atteint une taille énorme: 574 mm². (Il est assez amusant de constater que la GT200 reste la plus grosse puce actuellement).
En matière de processeur de flux, la GT200 dispose de 240 unités shaders, soit presque le double de la GeForce 8800. A l'image des Radeon HD3800 de AMD, la GT200 intègre les calculs en double précision. En plus précis, la composition des processeurs de flux est de 150 FMA32/INT, 30 FMA64/INT et 60 SFU. Le tout divisé en 30 blocs de 8 unités chacun comme les G80. Cadencé à 1296 Mhz pour une puissance théorique de 622 GFLOP en 32 bits et 60 GFLOP en 64 bits. Pour les calculs en nombre entiers, cela tourne aux alentours des 600 GIOP en 24 bits, 77 GIOP en 32 bits, et 17 GIOP en 64 bits. Cela pour la GeForce GTX 280.
Il est a noté que les 30 blocs sont mis parallèlement sous 10 blocs SM physique, et chacun de ses blocs sont reliés à un groupe d'unités TMU contenant 8 unités chacun pour un total de 80 TMU. Sous une fréquence de 602 Mhz, la performance atteint les 48160 méga-texels/s.
Autre changement important: le nombre d'unités ROP augmente jusqu'à 32 unités. organisé de la même manière que sous la G80, l'augmentation du nombre d'unité augmente donc le nombre de contrôleur mémoire G-DDR3 pour atteindre 8 contrôleurs pour un bus total de 512 bits. Les ROP sont à 602 Mhz et la performance culmine dans les 19260 méga-pixels/s, avec un débit mémoire de 142 GB/s.
Les modèles dérivés sont: GeForce 260 (avec 196 unités shaders), GeForce GTX 260+ (avec 216 unités shaders), GeForce GTX 275 (avec 240 unités shaders, mais sous un bus de 448 bits), la GeForce GTX 280 (240 unités sous un bus de 512 bits), la GeForce GTX 285 (surcadencée et gravée en 55 nm), et enfin la bi-gpu GTX 295.
Radeon HD4800:
Sortie peu après les GeForce GTX 280 et GTX 260, les Radeon HD4800 étaient une excellente alternative peu chère face aux TESLA GT200 certe plus puissantes, mais plus onéreuses.
Basée sur l'architecture WEKIVA RV770, les HD4800 ne sont pas une nouvelle architecture a proprement dite, elle est en effet issue des R600 qui animent les HD2900 et HD3800, mais en plus boosté, et surtout nettement améliorée et bien corrigée.
La puce RV770 dispose de 956 millions de transistors, un peu plus donc que les R600, mais beaucoup moins face aux dernières GeForce. Ce qui rend les puces Radeon plus économiques à produire. Étant gravé en 55 nm, la puce est très petite: 256 mm².
Le porte-étendard: la Radeon HD4870 dispose de 800 processeurs de flux réparties en 10 groupes vectoriels de 80 unités. En plus précis, elle se compose de 480 FMA32/INT, 160 FMA64/INT et 160 SFU. Sous une fréquence de 750 Mhz, elle atteint les 1200 GFLOP en 32 bits, et 240 GFLOP en 64 bits. Aucune information pour les calcul en nombre entier cependant..
Le nombre de TMU augmente à 40 unités sous 10 groupes de 4 unités. A 750 Mhz, la performance atteint les 30000 méga-texels/s.
Le nombre de ROP reste inchangé: 16 unités à 750 Mhz pour 12000 méga-pixels/s.
Le bus mémoire reste à 256 bits avec 4 contrôleur 64 bits sous une fréquence de 900 Mhz. Mais la HD4870 emploie la G-DDR5, ce qui offre un meilleur débit pour une fréquence plus faible et un bus moins large. Le débit atteint les 115 GB/s.
Les dérivés sont: La HD4850 (Moins cadencé et employant la G-DDR3), la HD4830 (avec 640 unités shaders), la HD4750 (comme la HD4830, mais sous un bus de 128 bits) la HD4890 (une RV790 qui optimise la consommation, et plus cadencée), et enfin 2 bi-GPU: les HD4870 X2 et 4850 X2.
La suite avec les Radeon HD5800 et GeForce Fermi.
AMD RyZen 7 2700X, ASRock X470 Taichi, 16 Go DDR4-3200 G-Skill (2x8 Go), Radeon RX Vega 64, Samsung 970 EVO 256 Go+500 Go, 850 EVO 250GB
Hors ligne
#7 2014-12-23 14:10:18
- Gael91
- New member
- Date d'inscription: 2013-11-15
- Messages: 20
Re: [VGA] Architecture des GPU
Je reviens vers vous^^. Occupé pendant un temps..
GeForce GF100/GF110:
ATI ayant sortie les redoutables Radeon HD5870 et HD5850, Nvidia sort avec un certain retard les GeForce GTX480 et GTX470 basée sur la nouvelle architecture FERMI. Nvidia a opté pour une autre direction, une architecture toute nouvelle qui met fin à la génération TESLA inaugurée par les GeForce 8800.
La puce atteint 3 milliards de transistors en 40 nm sous un die de 529 mm², légèrement plus petit donc qu'une Tesla GT200, mais ça reste énorme en comparaison de la concurrence.
On se base plus sur des Threads, mais des blocs SM réparties par des groupes GPC. Chaque GPC abrite 4 blocs SM, et chaque SM abrite 32 processeurs de flux. La puce en abrite 16 de ces blocs SM. Les SM abritent également chacun son lot d'unités TMU, 4 unités pour être précis. Les SM abritent également une unité de calcul spéciale: le Tesselator Engine (Aussi nommé le Polymorph Engine), destiné a calculer le tesselation. D'un coté, chaque GPC (cette fois-ci) abrite un Raster Engine (pour les calculs liés aux triangles). En tout, cela nous amène à 512 processeurs de flux, 64 TMU, 16 Polymorph Engine et 4 Raster Engine. Cependant, la GTX480 étant extrêmement gourmande, nvidia a bridée la puce en désactivant un bloc SM, ce qui nous rabaisse à 480 processeurs de flux, 60 TMU et 15 PE. Son successeur, la GTX580 disposera de la totalité des unités.
Pour le système mémoire, la GF100/GF110 dispose de 1536 Mo G-DDR5 à 384 bits avec 48 ROP au total, réparties par 6 contrôleurs G-DDR5 64 bits, donc 6 groupes de 8 ROP. Notons que la FERMI intègre une mémoire cache L2 de 768 Ko reliée aux contrôleurs GDDR par groupe de 6x128 Ko.
Les GeForce 500 seront des FERMI optimisées niveau consommation et la GTX580 aura le total de unités. Cette série aura une bi-puce avec la GTX590.
Notons que les versions gamme moyenne comme les GTX460 ou GTX560 Ti seront basées sur des blocs SM de 48 unités, et non 32 comme le haut de gamme.
Radeon HD5800:
Les nouvelles Radeon HD5800 seront les premières puces haut de gamme a être gravées en 40 nm et à prendre en charge DirectX 11. Disposant de prés de 2.2 Milliards de transistors, son die atteint les 334 mm², donc bien plus petit que les FERMI. Son nom de code est CYPRESS RV870.
Son architecture reste basée sur du VLIW5 comme ses prédécesseurs, mais avec beaucoup de modifications. On dispose de 20 blocs de 80 unités, donc 1600 processeurs de flux au total. On dispose également de 80 TMU, car 20x4 TMU. On a toujours 1 raster Engine et un tesselator engine avec un débit de calcul amélioré. Avec un fréquence de 850 Mhz, la HD5870 atteint les 2.7 TFLOPs en simple précision et 550 GFLOPs en double précision. Elle maitrise les dernières technologies de computing libre avec OpenCL 1.2 (Alors que nvidia reste en 1.1).
Le nombre de ROP augmente pour atteindre 32 unités avec un bus mémoire de 256 bits G-DDR5 avec 4 blocs de 8 ROP. Tout comme les FERMI, la CYPRESS intègre un cache L2 de 512 Ko.
Niveau consommation, elle fut un succès, car dépassant à peine les 190 Watts, bien mieux donc que les +250 Watts de la FERMI. Ses performances seront également excellentes, on a donc un bon rapport perf/conso.
Niveau technologie, elle instaura EyeFinity pour maitriser 6 écrans Full-HD qui sera un plus face aux limites de 2 écrans HD pour les FERMI.
Une bi-gpu sera présente: La HD5970 qui se révélera puissante, mais sans concurrence immédiate, vu que les GeForce 400 seront trop gourmandes pour être mit en double.
Dernière modification par Gael91 (2014-12-23 14:10:40)
AMD RyZen 7 2700X, ASRock X470 Taichi, 16 Go DDR4-3200 G-Skill (2x8 Go), Radeon RX Vega 64, Samsung 970 EVO 256 Go+500 Go, 850 EVO 250GB
Hors ligne
#8 2017-01-14 20:39:36
- Gael91
- New member
- Date d'inscription: 2013-11-15
- Messages: 20
Re: [VGA] Architecture des GPU
Après 4 années d'absence, je reviens vers vous^^ (Occupé par le CNAM et divers autres événements).
On continue notre rétro des GPU, mais avant d'aller plus loin, je tiens à rajouter un détail que j'ai omis dans mes précédents postes.
Ce détail concerne le fonctionnement des GPU, et surtout la principal différence entre un GPU GeForce et un GPU Radeon.
La différence principale est le fait que les Nvidia sont de type SCALAIRE et les Radeon de type VECTORIEL.
Rien que le fait que les Radeon HD2000/3000 ont par exemple pour nom "VLIW5" révèle cette particularité.
VLIW est l'abréviation de "Very Long Instruction Word". Ce qui veut dire quoi?
Observons la Radeon HD5870 qui selon les données disposent de 1600 shaders. Ce qui en soit faux et vrai à la fois. Faux physiquement, et vrai par la pratique.
Les Shaders des Radeon utilisent le vectoriel pour s'alimenter. Un shader est capable de prendre en charge plusieurs instructions ou données par cycle. Bien sur, le nombre d'instructions n'est pas fixe et elle est définit par l'architecture, et cette donnée est confié par le chiffre 5 de VLIW5. Cela veut dire que la HD5870 peut supporter jusquà 5 instructions par cycle en parallèle.
Donc, dans la réalité: la HD5870 n'a "que" 320 shaders présents physiquement. mais étant capable de supporter jusquà 5 instructions, la HD5870 dispose donc d'une puissance théorique équivalente à 1600 shaders en scalaire.
Contraire du scalaire qui se base sur une seule instruction par cycle.
Pourquoi avoir choisi cette architecture? parce qu'elle est plus économique. On met moins de "cores", et on les alimente au mieux avec un processeur de commande vectoriel performante. Il en résulte d'un GPU plus facile à produire, car moins complexe, et surtout plus petite en surface, et finalement, moins coûteuse.
Nvidia a opté pour du scalaire, car celui-ci a voulu déjà percer dans monde du computing avec CUDA, et le computing est plus aisé à employer avec du scalaire. AMD de son coté a voulu en premier lieu privilégier le public, et la 3D n'avait pas de problème à exploiter aussi bien le VLIW que le scalaire.
AMD a mit fin au VLIW avec les HD7000 GCN qui sont passés au scalaire afin de percer à son tour dans le GPGPU.
AMD RyZen 7 2700X, ASRock X470 Taichi, 16 Go DDR4-3200 G-Skill (2x8 Go), Radeon RX Vega 64, Samsung 970 EVO 256 Go+500 Go, 850 EVO 250GB
Hors ligne
#9 2017-01-15 09:06:30
- CornerJack
- Administrator
- Lieu: Belgique
- Date d'inscription: 2007-05-08
- Messages: 8812
- Site web
Re: [VGA] Architecture des GPU
Merci à toi et je confirme la qualité de ton post ! ![]()
Je vais surement pondre un test sur le GTX 1070 et 1080 sous peu, donc si tu veux faire une page de l'article afin d'expliquer cette nouvelle puce ![]()
Merci à toi.
Devenez un Lover'clex : http://www.facebook.com/overclex
Hors ligne
#10 2018-01-20 13:43:52
- Gael91
- New member
- Date d'inscription: 2013-11-15
- Messages: 20
Re: [VGA] Architecture des GPU
De retour ![]()
Un petit topo avec les GPU que nous avons en ce moment.
Les GeForce 10 de NVIDIA se montrent efficaces. L'architecture "Pascal" en soit n'est pas novatrice, car elle se base en réalité sur MAXWELL (Employée par les GeForce 900): on a toujours affaire à des blocs SMM de 128 shaders par exemple. Mais NVIDIA profite d'améliorer le rendement de ces unités SMM, de booster les capacités de fréquence avec le passage en 16nm. Il faut aussi voir que 2 type de "PASCAL" sont apparus: Les GeForce 10 sont les "PASCAL-G" où techniquement, elles sont proches des MAXWELL....et les PASCAL-T employé par la grosse puce GP100 dédiée aux professionnels. Celle-ci emploi une architecture bien différente avec des cores SMM de 64 unités, contenant des unités dédiés au FP64 (Pour les calculs avancés à haute performance, le secteur HPC), mais aussi le FP16 (Pour les calculs de Deep Learning ou IA). La GP100 atteint en effet dans les 5 TFLOP/s en FP64....et 24 TFLOP/s en FP16.....alors que la GP102 (Qui anime les GTX 1080 Ti et TITAN X ) dépassent à peine les 300 GFLOP/s. De plus, la GP100 utilisent la VRAM HBM2, certe coûteuse, et pas accessoirement plus rapide que la G-DDR5X (et la futur G-DDR6), mais qui dispose d'une latence extrêmement faible, un paramètre essentiel pour le HPC et Deep Learning. Le public utilise la G-DDR5X pour ses GTX 1080 Ti et GTX 1080, les autres employant la G-DDR5 classique la plus aboutie (Atteignant 2000 MHz).
Récemment, NVIDIA a officialisé la TITAN V se basant sur l'architecture VOLTA, avec la GV100. VOLTA que pour les pros, le public aura droit à une autre architecture nommée AMPÈRE. La GV100 se base sur la GP100, mais avec une nouveauté: les Tensors Cores, qui permet d'atteindre une puissance de calcul FP16 colossale de....120 TFLOP/s...
Du coté d'AMD, on a droit à POLARIS et VEGA.
POLARIS anime les gammes moyennes et bas de gamme avec les Radeon RX 400 et RX 500. Gravées en 14nm, elles concurrencent les GeForce GTX 1060/1050/1030 avec respectivement les POLARIS 10, POLARIS 11 et POLARIS 12. Niveau architecture, elle est identique aux anciennes puces TONGA et FIJI (les GCN3), elle se contente que d'améliorer le rendement perf/watt avec le passage en 14nm, et la mise à jour du moteur d'affichage (HDMI 2.0 entre autre).
VEGA est en revanche un changement en architecture. Passage en GCN5, elle concurrence que les GP104 (GTX 1070/1070 Ti/1080) pour le moment, mais pourrait atteindre les GP102 à terme. L'innovation principale est le FP16 à double vitesse pour 25 TFLOP/s, ce qui lui permet de concurrencer face aux GP100. La HBM2 est bien sur de la parti, mais rend compliqué sa conception, et rend la Vega lus cher.
Voila le résumé, je ferai une prochaine fois un beau tableau qui présentera plus de détail (Quand j'aurai le temps bien sur ![]() )
)
AMD RyZen 7 2700X, ASRock X470 Taichi, 16 Go DDR4-3200 G-Skill (2x8 Go), Radeon RX Vega 64, Samsung 970 EVO 256 Go+500 Go, 850 EVO 250GB
Hors ligne
#11 2018-01-20 14:41:16
- CornerJack
- Administrator
- Lieu: Belgique
- Date d'inscription: 2007-05-08
- Messages: 8812
- Site web
Re: [VGA] Architecture des GPU
Merci à toi Gael91 ![]()
Devenez un Lover'clex : http://www.facebook.com/overclex
Hors ligne
#12 2018-01-20 20:20:04
- Gael91
- New member
- Date d'inscription: 2013-11-15
- Messages: 20
Re: [VGA] Architecture des GPU
Voila la tableau comme promit ![]()
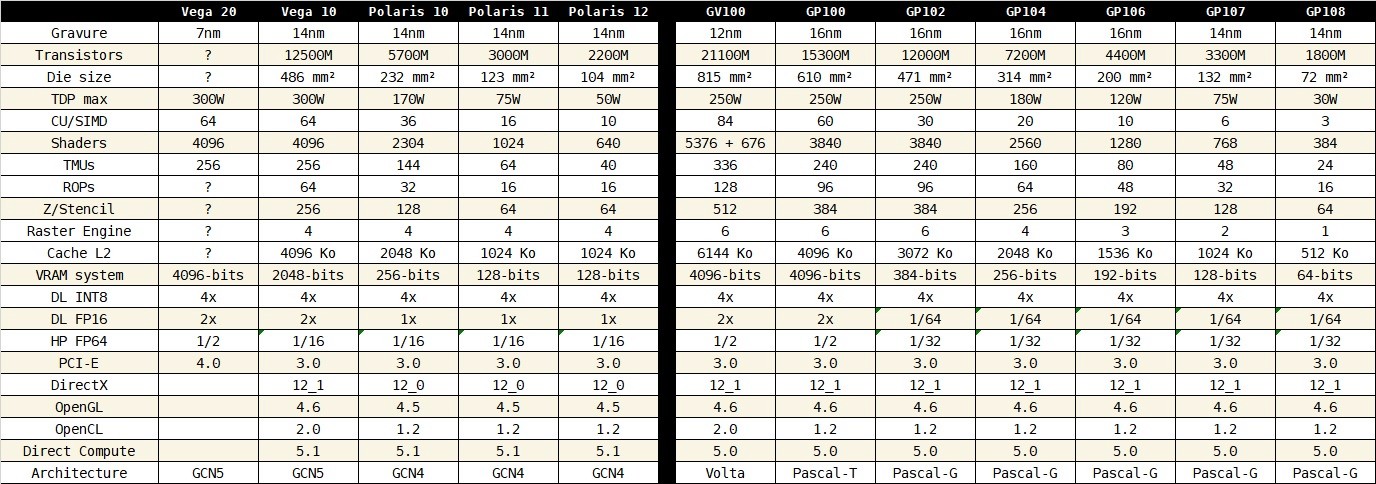
PS: Ouvrir l'image dans un nouvel onglet pour mieux la visualiser
Dernière modification par Gael91 (2018-01-20 20:20:39)
AMD RyZen 7 2700X, ASRock X470 Taichi, 16 Go DDR4-3200 G-Skill (2x8 Go), Radeon RX Vega 64, Samsung 970 EVO 256 Go+500 Go, 850 EVO 250GB
Hors ligne
#13 2018-01-21 20:25:52
- CornerJack
- Administrator
- Lieu: Belgique
- Date d'inscription: 2007-05-08
- Messages: 8812
- Site web
Re: [VGA] Architecture des GPU
Gael91 a écrit:
Voila la tableau comme promit
https://i62.servimg.com/u/f62/13/94/54/05/gpu_pr10.jpg
PS: Ouvrir l'image dans un nouvel onglet pour mieux la visualiser
Parfait ![]()
Devenez un Lover'clex : http://www.facebook.com/overclex
Hors ligne